|
Master Member
  加入日期: Nov 2010
文章: 2,414
|
FX8350的浮點運算性能比想像中的好
簡單來說事情是這樣
我寫了一個FEM的程式,本來是單緒的 計算瓶頸主要在LU分解(大概整個流程有90%的時間在LU分解) 最近我找到了多執行緒LU分解的方法,所以改寫程式讓程式可以多執行緒LU分解 測試一下3570可以跑3570單緒的3.2倍快,雖然跟預想有落差,但只更改少少的程式碼就有這樣的成果也不錯 然後無聊測一下FX8350的多執行緒狀況,想說FX8350只有4個浮點運算器,又比3570弱,所以應該比3570更花時間 ...結果FX8350多緒跑的速度大概是3570單緒的4.8倍快,也就是說讓FX8350全速跑比3570全速跑快50%左右 ") 後來在想會不會是因為我的程式中浮點數精度設定是double(64bit) 對推土機架構來說浮點數精度來到256bit時浮點運算器才是算4個 對128bit以下的浮點數其實還是算8個浮點運算器? 所以沒有模塊中兩個核心爭奪浮點運算資源的問題? 不過程式中沒有改成多執行緒的地方FX8350明顯比3570慢就是了
__________________
新。弱弱的戰績  
此文章於 2015-09-18 08:33 PM 被 commando001 編輯. |
|||||||
 2015-09-18, 08:30 PM
#1
2015-09-18, 08:30 PM
#1
|

|
|
*停權中*
加入日期: Jun 2015 您的住址: 金一十大女支三
文章: 1,282
|
程式的問題 如果能充分利用AVX
DP per cycle 3570是FX8350兩倍 |
||
|
2015-09-19, 01:08 AM
#2
|
|
|
Advance Member
加入日期: Jun 2013
文章: 416
|
並沒有8組浮點運算這回事
4組永遠是4組 一對CPU同時只能有一個使用FPU 之所以被很多人誤解有8組 是因為類似SSE擴展指令集AVX 可以一次計算2組浮點數 一個CPU同時使用AVX計算2個浮點數 跟2個CPU可以個別計算一次浮點數 可是完完全全的不一樣 浮點運算器不可分割使用 我不瞭解你用的算法 不過如果使用了SSE擴展 或是改用VS2015編譯 對效能都是有幫助的 |
|
2015-09-19, 01:59 AM
#3
|
|
|
Elite Member
加入日期: Jan 2002
文章: 4,038
|
能不能發揮硬體的性能,永遠取決於軟體本身及作業系統!!
樓主的案例是取決於軟體本身 , 用multi-thread可以增進執行效率 , 主因還是不能夠有 data dependency , 如果發生相依性,想快也會快不起來....
__________________
您想買新硬碟嗎? 購買前請務必參考這篇文章,是我的實際經驗 還想讓統一賺你的錢嗎?統一集團成員(能見度高的): 星巴克、家樂福、7-11、無印良品、黑貓宅急便、聖娜多堡、阪急百貨、 康是美、博客來、夢時代、Mister Donut 、Cold Stone 、龜甲萬、 維力33%股權、光泉31%股權、Smile速邁樂、紅心辣椒、台北轉運站(統一企業BOT) 統一LP33膠囊有環保署早已列管的一級管制品: DNOP塑化劑 |
|
2015-09-19, 08:54 AM
#4
|
|
|
Regular Member
 加入日期: Apr 2001 您的住址: Taipei, ROC
文章: 85
|
引用:
正解! 4組就是4組,不可分割,在AMD官方文件內載明。 |
|
|
2015-09-19, 10:28 AM
#5
|
|
|
Master Member
加入日期: Nov 2010
文章: 2,414
|
引用:
剛剛查了一下,編譯器本身不支援AVX(我用的語言是現在很冷門的delphi) 那就蠻奇怪的,如果還是一組,那代表FX8350的浮點運算器性能約為3470的160% 可是在原本單執行序的程式碼部分FX8350就是慢很多... 剛剛查了一下推土機架構的圖 http://www.anandtech.com/show/2881 裡面的內文 Behind the FP scheduler are two 128-bit wide FMACs. AMD says that each thread dispatched to the core can take one of the 128-bit FMACs or, if one thread is purely integer, the other can use all of the FP execution resources to itself. 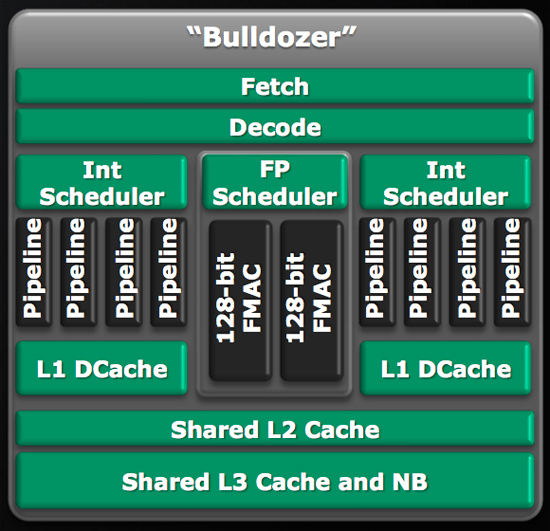 模組中都在做浮點運算時每個核心都會拿到1個128bit FMAC來做運算 所以推土機系列的浮點數運算器算是能拆的? 引用:
因為我的程式碼內沒有用synchronized...所以真的有data dependency,會算出一堆垃圾 
__________________
新。弱弱的戰績
|
||
|
2015-09-19, 11:47 AM
#6
|
|
|
Advance Member
加入日期: Jun 2013
文章: 416
|
3470 4核心, 你用的是8核
要知道一個問題 你如何得知90%的效能花在浮點計算? 以常識來說 這幾乎不可能 尤其你使用的是delphi 再忙碌FPU跟CPU的比率 很難超過60%以上 想超過這個瓶頸 必須在busy loop動手腳才能辦到 原因在於迴圈跳躍的動作 遠比想像中的緩慢 通常加速的方式 就是 一個loop中 寫入8份的計算, 這樣loop的跳躍次數只需要8分之1 |
|
2015-09-19, 12:42 PM
#7
|
|
|
Regular Member
加入日期: Mar 2015
文章: 66
|
引用:
不能拆,您應該以AMD官方編號47414的Software Optimization Guide為準: ========================================= "The FPU can receive up to four ops per cycle." ===> 每個時脈內,FPU可以接受最多4個微指令 "These ops can only be from one thread," ===> 這些(最多4個)微指令,必須是來自同一個執行緒(該時脈內) "but the thread may change every cycle." ===> 但是每個cycle,可以切換成不同的執行緒(來使用整個FPU) ========================================= FPU是不能拆的,而是以cycle為單位,讓兩個執行緒輪流使用。 |
|
|
2015-09-19, 05:29 PM
#9
|
|
|
Master Member
加入日期: Nov 2010
文章: 2,414
|
引用:
看了一下你說的東西感覺不太對勁 我是說計算時間90%在LU分解啊 至於你說的東西是這個吧?循環展開 看了下作法大概沒辦法實作就是了,因為for的次數不是固定的就很難處理展開式,編譯器...大概也不支援動態展開 LOOP會造成執行效率低下我知道了,但是兩邊loop數量都是一樣的(同個程式) 那造成速度差異的部分不就剩多執行緒LU分解中的加減乘除性能和讀寫RAM 以及同時處理的執行緒數量?
__________________
新。弱弱的戰績
|
|
|
2015-09-19, 06:25 PM
#10
|
|





