引用:
|
作者lzarconlony1
一般都是看decoder之後那段來決定...過程不重要 結果是一切
Predecoder這段 查了很久確定到Skylake都是16B with 6 instruction
K8/K10 32B with 3 ins. Bulldozer 32B with 4 ins.
Streamroller有點不好說 32B但不清楚到底4還8 可信資料不足
而Zen應該是32B with 4 ins. 已經取過多也取不夠多 不知道decoder會不會改
simple decoder可能有專利?
fetch不是越多越好 而是要搭配cache跟scheuling
CPU是一個整體 pipeline上面要均衡
我認為Bulldozer當初做太多Predecoder這段 Steamroller增加decoder
很明顯就是取太多但是後面跟不上 才會這樣改
因為還需要其他搭配 例如Skylake有標明 那個數據是Win 10 x64下的結果
你沒用這個OS 沒用AVX是達不到相同IPC & Flops
AMD資料超難找
http://ieeexplore.ieee.org/xpl/logi...3A%2F%2Fieeexpl... |
intel的斯斯有兩種,p6跟p8架構
直到2代Core i才是真正的把p6跟p8架構的優點整合在一起,
scheule那邊看起來都差不多是因為Predecode之後都是沿用改良P6架構,
但是Predecode之前改良自p8架構。
http://bolgimg.b0.upaiyun.com/image...36DC5C93%7D.jpg
SNB這一代會有明顯的進步是因為Predecode之前這一段整個砍掉重練
fetch到Cache都比前代的Nehalem大,新設的Rop cache就是以前的Trace Cache
印象中NetBurst的缺點是命中率太低,所以花了很大的心力在演算法上面。
當資料的吞吐量變大有利於多工,後面的HSW跟SKL都是朝這個方向改進(不過不知為何要堅持用16B)
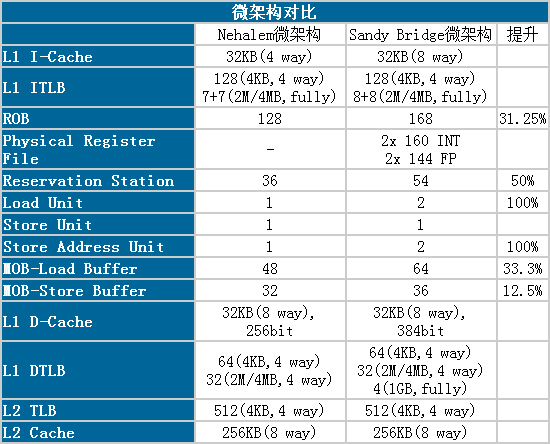
AMD的Bulldozer對Predecode之後作了改善,但L1 IC那邊的老問題一直沒解決
畢竟SRAM的造價昂貴,64KB 2路跟32KB 8路比較雖然容量較大,但頻寬差一大截
(多路的缺點是延遲,所以intel每跳一代都把延遲都減少一倍),當然還有另一個目的
"繪圖功能"
insttruction fetch到Predecode這邊,intel用大量的多緩衝解決16B寬度不足的問題,
而且也考慮到功號問題。
intel在後段的效率其實已經很好,當然也增加了很多緩衝增加靈活性。
我想未來intel會朝向Fine-grained multithreading(FMT,細質多執行緒)
這個方向走,等拉高資料的吞吐量之後再多一組decode也不是難事。
畢竟Yonah之後都維持現在1+3這個規模。