PCDVD數位科技討論區
(https://www.pcdvd.com.tw/index.php)
- 七嘴八舌異言堂
(https://www.pcdvd.com.tw/forumdisplay.php?f=12)
- - Ollama for Gemma 4
(https://www.pcdvd.com.tw/showthread.php?t=1218133)
|
|---|
Ollama for Gemma 4
我用的好爽呀…
跟Germini 4沒什麼差別。 不過我想換成6090了。 還有128GB的系統記憶體可能也是不夠用的。 |
手上機器雖多,一直沒湊一台最好的。
用目前常用的電腦(就是上網,看影片、論壇,i5 9400 / 32GB / GTX 1660) 反而用 opencode + 一些免費額度,已經生出 3,4 個可以自動化掉我上班的工作。 原本不太想為一堆要花半小時到2小時之間的工作弄個 RPA 自動化,沒啥效益。 但現在用 AI 開發一些小工具,花的時間縮短很多。 一下子就產出 3,4 個能處理重複性工作的小工具。 而給 ollama 用的是最簡單工具,連我寫都比它快的。(因為免費額度還在 CD) 速度就像初學者打字一樣。CPU / RAM 全滿載。 跑出的結果,幾乎是 try & error。都想弄台 DGX Spark 玩。 PS: 80年代我花在電子電腦的錢...想起來就恐怖。 以前靠 RAM 顆粒賺幾十萬,一瞬間就花光,現在幾十萬下不了手。 加上 DGX Spark 光電費可能用噴的。 |
砸錢多買幾張卡. :)
|
引用:
請向你尋問一下,有沒有可能製作一個可以加速本地部署的大語言模型加速卡? |
引用:
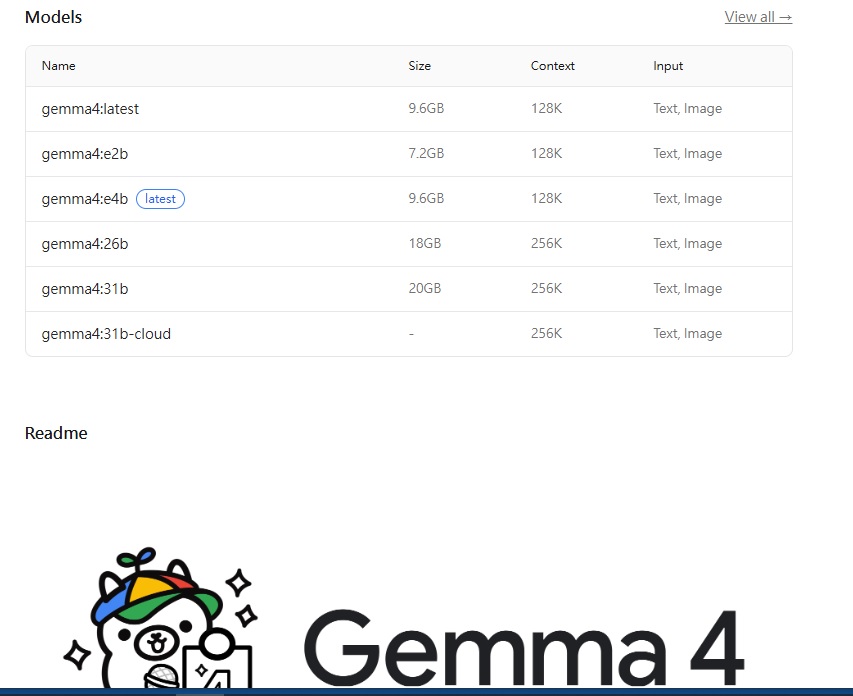
就老黃的阿,畢竟資源多。有雷至少有人先踩。 不然消費級的就顯卡,不玩 AI 遊戲也可以用。 有人用 Mac Pro 頂規 25 萬,仍有天花板。 畢竟所謂的記憶體共享,是裝成 共享。 跟真共享還是有差,不過消費級不可能做真共享。 硬體要極度優化設計,不可能有冗餘。 我不是專業的, FB/YT 上有一堆高手,都有餘裕拍影片、分享文章。 問他們應該比我好,我是喜歡玩玩新玩意。 弄弄小工具,擠出更多時間摸魚...進行研究。 (老了,已經沒以前可以一個禮拜不睡) 剛拉 Gemma 4 下來跑,資源占用小很多(現在還可以打字) 中午看到 Gemma 4 release 時,就 pull 下來。 但寫到一半,怕 session 斷掉,就沒換掉原本的 model。 沒想到差這麼多,就算 對話(session) 斷掉重來,也比在用原模型快多了~~~ 這篇還沒打完,就幫我做好重構。 |
引用:
我的意思是,總是有看到人想要買mac mini去養蝦… 又看到很多人想要大模型。 但是大模型要配5090或是超大的256GBDDR5,還要再搭上threadripper之類的。 怎麼就沒有人想過要特別設計一張一般人買得起,一切整合好的超級算力卡? 直接上算力加速,64GB的HBM3 Unified Memory,再配上128GB的DDR5? 就跟以前的礦卡一樣,出一張算力卡。 這樣一般的家用電腦三萬多,再配上一張算力卡,就能提供本地大模型。 不用5090,不用配上128GB的DDR5,CPU只要有核顯,主板有32GB DDR5就夠了,連Win11都只要家用版,水冷也不用。 套裝機買下去,再配上算力卡,一切搞定。 |
 |
引用:
養蝦 主要是沒效率,很多 token 都浪費掉。(現在開始封不是自家 agent) 所以才想用本地,但養蝦透過雲才能減少負載。 規格可以爛點,畢竟都上雲跑(但隱私也可能裸奔)。 硬體規格沒啥要求,一堆還宣傳用樹莓、N100、N150。 要落地跑大模型,配備不能太差。 天花板就是看 $$$,電費 $$$。 https://www.youtube.com/watch?v=jTVKagbUA68 https://www.freedidi.com/23643.html 八、使用建議(非常重要) 根據你的顯示卡來選模型: 8GB 記憶體👉選擇小模型 12GB👉中量化版 24GB👉推薦26B 或31B 不要盲目上最大模型,否則會: ❌卡頓嚴重 ❌推理速度慢 model 進步那麼快,硬體規格應該是會慢慢降低標準。 |
相關群:
https://www.facebook.com/groups/3238547836318385/ 某人測試報告: https://www.facebook.com/share/p/1GDQvBtSJN/ 一堆神人都先測試了,還有報告。(很多這類的) |
不要用 ollama
ollama 難用、性能差、假開源 而且它底層是用 llama.cpp 我完全不懂為什麼它的性能可以差成這樣 單用 llama.cpp 更簡潔,性能更強 |
| 所有的時間均為GMT +8。 現在的時間是03:33 PM. |
vBulletin Version 3.0.1
powered_by_vbulletin 2026。